Framework-agnostic browser-based SPA
1. But… why?
- There are a lot of frontend frameworks.
- There are a lot of tutorials and documentation showing how to build an application using particular framework.
- But usage of the particular framework as a main driving force for application architecture is much like the tail wagging the dog.
Given how hype-driven the software development industry these days, you may be sure that in a couple of years new frameworks/libraries will ride the edge of frontend development. As soon as the framework of today’s choice goes out of the trend - you will be either maintaining the “legacy” codebase or starting the re-write of the whole UI application. Both options are sort of stealing from the customer. Re-writing of the application due to framework change doesn’t introduce any benefits to business. Maintainance of the “legacy” codebase drastically reduces the motivation of the team and subsequently - individual developers performance.
This article shows how the UI could be built based on the high-level design patterns. Concrete frameworks/libraries are chosen only in order to cover responsibilities, defined by architecture.
2. Architectural goals and limitations
Goals:
- New developer can take a brief look on the code structure and get an intent of application
- Force developers to sepation of concerns and thereby force the code to be modular so:
- When we do some nasty hacking OR want to integrate with external boundary - code does not spill through multiple files and therefore it’s replacement become a realistic task rather then “abstract long-term refactoring”.
- Modules are testable
- Force logically related things to be located close to each other in the folders structure and avoid the need to search for very related code in very distant folders. Check the article covering the differences between the code separation by technical tier rather than by functional responsibility.
- Account for loose coupling between modules so changes to implementation details of particular module (or replacement of this module) do not affect other modules as long as interfaces are met
- Mechanics chosen for modules integration does not introduce inaccepatable performance issues.
- Dependencies on particular libraries are not spilling through the whole codebase, but being manageable within a limited amount of codebase, responsible for integration with such a libraries/frameworks.
Limitations:
Application should run in browser. Subsequently it should be written (or compiled into) the HTML+CSS for static UI and JavaScript for adding dynamic bahaviors to this look.
3. Narrow down the article scope:
There are a plenty of high-level approaches to code structuring. The most noticible are layered, onion and hexagonal.
This article is scoped to reflect only the presentation layer of layered/onion because the wast majority of the SPA are primarily focused on showing the data. So these applications could simply bypass Domain layer entirely and have a tiny Application layer (or bypass this layer as well).
Subsequently, the most convenient way to understand the intent and the purpose of such an application is to get an overall picture of the presentation-related code.
However, this article describes mechanics for usage of the domain- and application-level functions/classes if your application have such a layer(s).
Notice that if both layers are bypassed you end up in classic Hexagonal (so called Ports and Adapters) approach where your presention IS your application. Check out how the integration with local storage is extracted to the boundaries/local-storage folder within the TodoMVC sample.
4. Files structure. How to make the SPA scream?
Let’s take a look on the typical online shop. This is how it would be likely drawn on a nakpin by a customer:
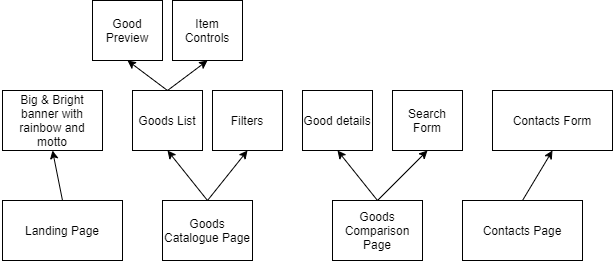
Figure 1: typical online shop structure, drawn on a napkin
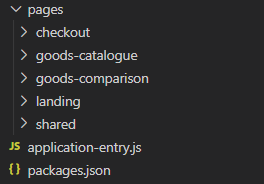 Figure 2: top level folders structure, which reflects logical structure from figure 1
Figure 2: top level folders structure, which reflects logical structure from figure 1
What could be the most screaming way to structure the codebase? Check the figure 2. All top-level blocks are reflected as separate folders.
Notice that we haven't forgotten to add a 'shared' folder in order to reflect all 'shared' UI blocks, such as layout, navigation bar, basket.
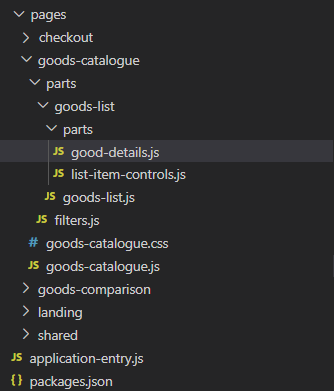 Figure 3: placing page sub-parts within the 'parts' folder
Figure 3: placing page sub-parts within the 'parts' folder
Our pages are built from the logical (and visual) parts. By now let's call them 'parts' and drop in the folder with same name. Take a look on what we've got on the figure 3.
Seems that nesting becomes annoying once we have the second level of hierarchy in 'goods catalogue' page. Path goods-catalogue/parts/goods-list/parts/good-details.js is already on the edge of reasonable path lengh. While this is not the deepest hierarchy we'd potentially have in the real application.
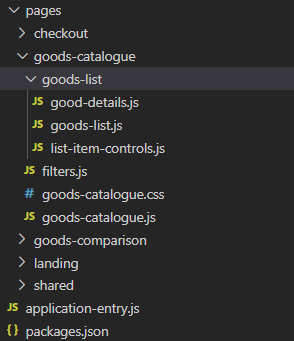 Figure 4: hoist the sub-parts from the 'parts' folders
Figure 4: hoist the sub-parts from the 'parts' folders
Now, let's get rid of unnecesary "parts" leaf in folders structure. Check the figure 4.
Now inside the goods-catalogue/goods-list we have three files. goods-list.js (parent one) - is located in between of the files, used for the definition of the sub-parts. On the real-scale projects, giving the presence of multiple files (styles, js, html, you name it) this will results in a mess an inability to distinguish between the part and it's sub-parts.
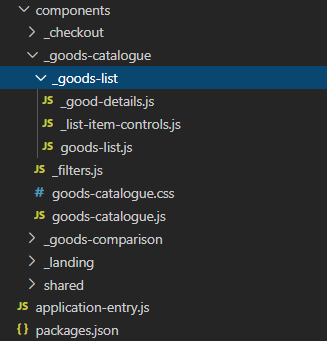 Figure 5: application of the underscore to distinguish between the part and it's subparts
Figure 5: application of the underscore to distinguish between the part and it's subparts
The solution:
-
If particular part is composed from multiple files - create a folder for it.
- goods-list is a part consiting of more than one file, so it have a dedicated folder.
- Filters is the part consisting of a single file - so drop this file without creation of separate folder for it.
-
If a particular part (either one-file part or multiple-files part) is a sub-part - prefix it with the underscore "_" sign. This way, all sub-parts (child items) are pinned to the top of the folder in the files explorer.
- _goods-list folder is a sub-part of goods-catalogue so it is prefixed with underscore.
- goods-list.js relates directly to the folder it locates within, so it is not prefixed with underscore.
- _good-details.js is a sub-part of goods-list so it is not prefixed with underscore.
Done! Once you get used to this approach, a brief look on every folder will let you instantly identify the sub-parts and open the file, used to assemble all these sub-parts together. Notice, that folder pages was renamed into the components on the last screenshot. It is done because pages and page parts are logically different things, but in html terms both can be called a component. So from here onvards, folder components become the main folder of our application and become a "home" for the presentation layer of SPA.
5. Programming language. JavaScript?
The only language which can be executed in the browser is JavaScript. There are a lot of articles describing how cumbersome it is. You can laught about it (timecode 1-20), but it is just a funny part…
What’s important to notice is that the new features are being constantly added to JavaScript. The Specification is being updated every year. All new features comes through the 4-stages review process before being pulled into the specification. But many times they are being adopted by browsers “before” reaching stage 4. And many times community and framework authors starts using features before they are being included into the specification. For example, decorators started being widely used in 2015, while still not being included in the specification. In the other hand, often times business requires an application to works in old browsers, lacking the support of newly introduced features.
Therefore even if you are using plain JavaScript, you have to use a transpiler (babel) to make a “browser-compatible” JavaScript from the “wild-and-modern” JavaScript. Since the use of the transpiler is inevitable - there is no reason to restrict yourself from using another, more safe, more fancy and more useful language and compile it to JavaScript instead of using plain Javascript.
Deep analisis of available options is out of the scope of this article, but my personal choice is the TypeScript because:
- Provides compile-time types checking
- Being a superset of JS, it can execute imported JS functions as a part of it’s own codebase without any additional integration code.
- Type definitions (typings) can be added on top of existing JavaScript codebase without affecting this codebase. Given the simplicity of adding the typings, the majority of npm packages already have them and therefore almost every single third-party JavaScript library could be consumed by your application as a TypeScript library. So most of the time integration with external libraries is also type-safe.
Hint: i’d suggest to take a look into asm.js, blazor and elm if you’re interested in other options
6. Software design targets:
Let’s remember the limitations, applied by the browsers: HTML, CSS, JavaScript. Remember the file structure we want to have (chapter 4) - folders tree which mirrors visual elements tree.
So the first target [6.1] is to let the components be defined using HTML and CSS and then re-used.
One huge disadvantage of pure HTML is that it is not strictly typed. There are plenty of templating engines, such as underscore.js, handlebars.js but they are designed to consume pure strings as an input. This prevents us from compile-time check on templates validity.
So the second target [6.2] is to ensure that we can define TypeScript interfaces to reflect all properties, used within the component. And then during compile-time throw an error if an unknown property is accessed within the component or an unknown attribute is defined on component in the html markup.
Every UI element on the page might have different states based on some data. Native HTML elements receive this data as html attributes. This is enough for static markup. For dynamic markup we want to have the data storages with values being changed while the user is working with the application. Same time, we shouldn’t lose an ability to pass the data to components through the attributes.
So the third target [6.3] is to let the components to consume data from both attributes and data stores. Let components be re-rendered when data is changed.
And the fourth target [6.4] - define data stores specification:
- let the data stores be shared between different components in order to reuse a single source of truth between multiple tiny UI components reflecting “parts” of the dataset.
- let the data stores be created per-component in order to support scenarios where different components have separate datasets behind them.
- let the data stores use domain and/or application services. In order to avoid tough coupling between the presentation layer and application boundaries, services shall be consumed using Dependency Injection. Data stores should only rely on the interfaces.
Finally, we don’t want the data in data stores being public so it can not be accidentally changed during the component’s rendering or within the event handler, defined in the component. We want to keep components as dumb as possible and make them nothing complex than the strongly-typed-and-optimized-html-templates. In order to achieve this, let’s keep the state of data stored encapsulated within these stores, exposing the methods for access/modification of such a state. In other words, let’s define our stores as old-fashioned classes.
However, as I’ve mentioned above, the data store might be shared as a single source of truth by multiple tiny components. In this case we want to have a very explicit visibility of the data slice, consumed by concrete component. This serve:
- Code readability (developer can guess the component purpose by seeing data it receives).
- Performance (re-renders of the component could be avoided if data, not related to the effective data slice, is changed).
So the fifth target [6.5] - let the data stores be defined as TypeScript classes, define mechanics to identify the slice of data, required by particular component.
With these targets in mind, let’s define following logical pieces code units:
- components - strongly typed html template + css stylesheet
- viewmodels - classes, encapsulating the state of the hierarchy down the component and exposing the methods for access/modification of such a state.
- viewmodel facades - limit the visibility of viewmodel properties to ones, required by a particular component.
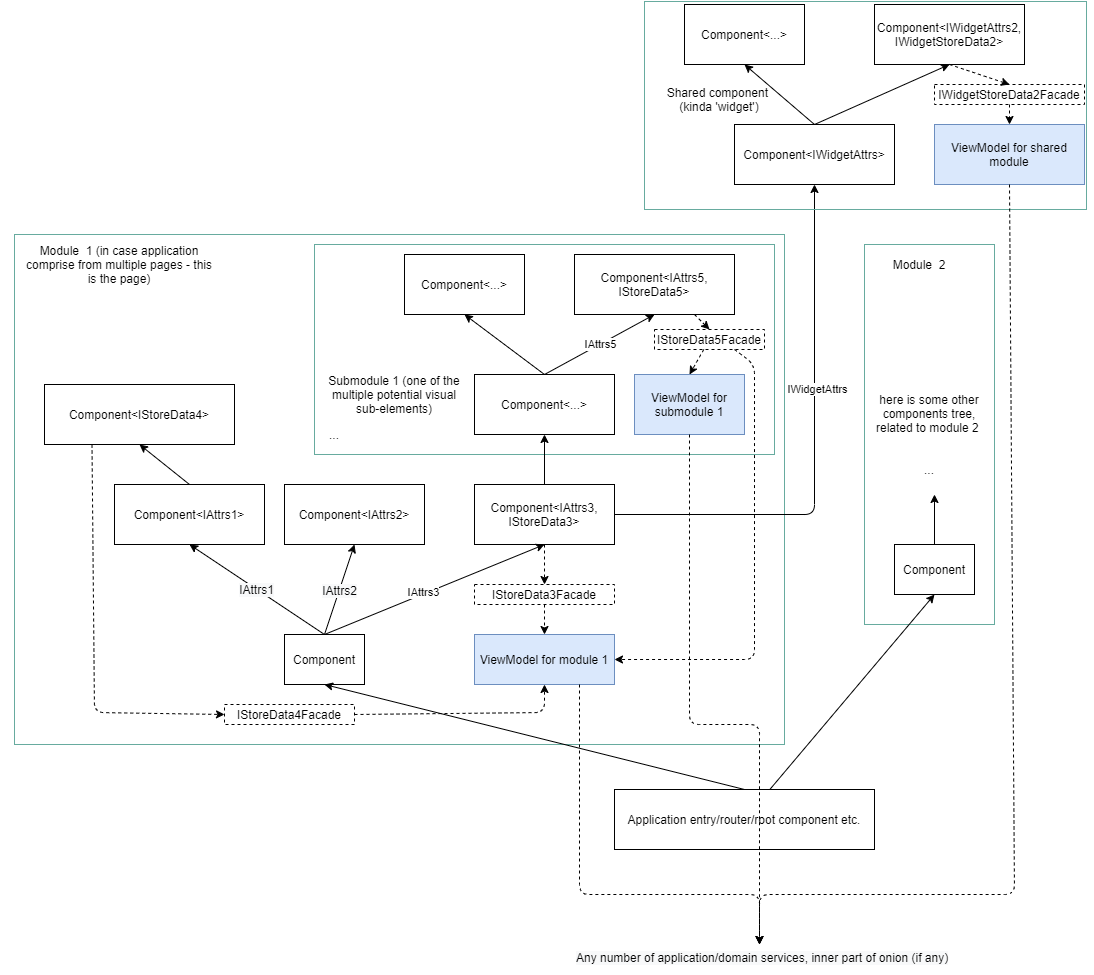
Figure 6: desired design of presentation layer
- Solid arrows reflect components being rendered by parent components, with attributes set supplied directly in the markup.
- Dashed arrows reflect code units being referenced by other code units.
- Blocks with green border - module boundaries. Each module/submodule is represented by a dedicated folder. Shared modules lay within the "shared" folder.
- Blue blocks - viewmodels. viewmodels are defined "per module/submodule".
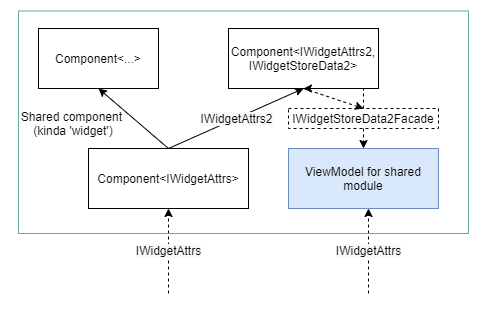
Figure 7: attributes should be passed not only to the root component of module, but also to it's viewmodel
Don't we miss anything? Notice that the viewmodels on the figure 6 does not have any parameters. This is always true for the "top-level" or "global" viewmodels. But submodule viewmodels, as well as shared modules viewmodels may frequently rely on the parameters, defined during the application execution.
So the sixth target [6.6] - let the attributes of the sub-module to be consumed by the viewmodel of this sub-module.
7. Technical choices:
I am going to use mainstream libraries in order to make this article easier to read. Hence there will not be a detailed comparison of different options - the most popular library will be used.
7.1. Components:
We want to have a library, which would allow the strongly-typed html markup definition. This can be achieved by using tsx (typed jsx) syntax, supported by libraries such as React, Preact and Inferno. Tsx is NOT the pure html, however it can be automatically converted to/from pure html so we are fine if at some moment we decide to switch into ‘pure’ html.
In order to reduce dependency on a particular library, let’s limit views to be a pure functions, receiving attributes and returning JSX node. This is the approach proven by/stolen from early-days react’s functional components.
hint: during the last few years react components have become side-effect-full with introduction of react hooks. This is a brand new story, hooks should not be used while working with the approach, described in this article.
In other terms, ‘components’ are stateless. Think about them through the simple equation UI=F(S) where
- UI - visible markup
- F - component definition
- S - state of current values within the viewmodel
Example component looks like this:
interface ITodoItemAttributes {
name: string;
status: TodoStatus;
toggleStatus: () => void;
removeTodo: () => void;
}
const TodoItemDisconnected = (props: ITodoItemAttributes) => {
const className = props.status === TodoStatus.Completed ? 'completed' : '';
return (
<li className={className}>
<div className="view">
<input className="toggle" type="checkbox" onChange={props.toggleStatus} checked={props.status === TodoStatus.Completed} />
<label>{props.name}</label>
<button className="destroy" onClick={props.removeTodo} />
</div>
</li>
)
}This component is responsible for rendering of the single todo item within the TodoMVC app.
The only dependency we have in this code is the dependency on the JSX syntax. So this component can be rendered by any library, which can render JSX markup. With this approach, replacement of a particular library will still not come for free, but is manageable.
So we handle targets [6.1] and [6.2].
note: i am using react for referenced TodoMVC demo application.
7.2. ViewModels
As it was mentioned in the chapter [6], we want ViewModels to be written as classes in order to:
- Allow internal state encapsulation
- Account for integration with domain/application layers using the dependency injection principle.
But classes do not have built in mechanics for automatic re-render of the components referencing the data, encapsulated by the class instance.
We need something, called reactive UI. The comprehensive coverage of the principles can be found in this doc. This approach was initially introduced in WPF (C#) and was called Model-View-ViewModel. In the JavaScript world, objects served as observable data sources are mostly called stores following the flux terminology. However, a store is a very generic term, it can define:
- Global data storage for the whole application
- Domain object, encapsulating domain logic, neither bound to particular component, nor shared across the whole application.
- Local data storage for a concrete component or components hierarchy
So every viewmodel is a store, but not every store is viewmodel.
Couple more limitations we want to apply to viewmodels.
- Code, related to reactivity, should not be blended with the feature-specific code.
- ViewModel shall not reference components and should now know that there are the compontens, referencing this viewmodel.
For now, i am going to us the mobx library and use decorators to make the regular class fields observable. Take a look on the example viewmodel:
class TodosVM {
@mobx.observable
private todoList: ITodoItem[];
// use "pure man DI", but in the real applications there todoDao will be initialized by the call to IoC container
constructor(props: unknown, private readonly todoDao: ITodoDAO = new TodoDAO()) {
this.todoList = [];
}
public initialize() {
this.todoList = this.todoDao.getList();
}
@mobx.action
public removeTodo = (id: number) => {
const targetItemIndex = this.todoList.findIndex(x => x.id === id);
this.todoList.splice(targetItemIndex, 1);
this.todoDao.delete(id);
}
public getTodoItems = (filter?: TodoStatus) => {
return this.todoList.filter(x => !filter || x.status === filter) as ReadonlyArray<Readonly<ITodoItem>>;
}
/// ... other methods such as creation and status toggling of todo items ...
}Notice that we reference mobx directly, but decorators are never spilling through the method bodies.
I’ll show you how to abstract out the reactivity and remove dependency on mobx in the next article. For now it is enough to just prefix the decorators with the ‘mobx’ namespace. The moment the developer decides to change the reactivity providing library - namespace might be replaced with another one using an automated script.
Also notice that ViewModel receives the first argument of type {status: TodoStatus} in the constructor. This accounts to the target [6.6]. The type is matching the attributes of the root component of the module. Below is generalized ViewModel interface:
interface IVMConstructor<TProps, TVM extends IViewModel<TProps>> {
new (props: TProps, ...dependencies: any[]) : TVM;
}
interface IViewModel<IProps = Record<string, unknown>> {
initialize?: () => Promise<void> | void;
cleanup?: () => void;
onPropsChanged?: (props: IProps) => void;
}Notice that all methods of IViewModel are optional. They might be declared on the viewmodel in case we want to ensure that:
- Code is executed when the viewmodel is created
- Code is executed when the viewmodel is deleted
- Code is executed when attributes of the (sub-)module is changed
Opposite to components, viewmodels are statefull. They must be created once the module appears on a page and deleted once the module is removed from the page. And as it is shown in the figure 7, the top level component of the module is an “entry” of this module. So the viewmodel should be created when the component instance is created(mounted) and deleted when it is deleted(unmounted). Let’s handle this with the higher order components technique.
Consider having the function of following signature:
type TWithViewModel = <TAttributes, TViewModelProps, TViewModel>
(
moduleRootComponent: Component<TAttributes & TViewModelProps>,
vmConstructor: IVMConstructor<TAttributes, TViewModel>,
) => Component<TAttributes>such a function shall return a higher order component over the moduleRootComponent which:
- must ensure that the viewmodel is created before the creation (and mounting) of the component.
- must ensure that the viewmodel is cleaned up (aka deleted) when the component is being unmounted.
You can check the implementation used for referenced TodoMVC app. This implementation is a bit more complex than described one in order to handle custom IoC container and re-creation of the viewmodel in responce to attribute changes.
Now let’s see the example of usage of this function:
const TodoMVCDisconnected = (props: { status: TodoStatus }) => {
return <section className="todoapp">
<Header />
<TodoList status={props.status} />
<Footer selectedStatus={props.status} />
</section>
};
const TodoMVC = withVM(TodoMVCDisconnected, TodosVM);Within the markup of application entry page (or root router, whatever you prefer) it is to be called as <TodoMVC status={statusReceivedFromRouteParameters} />
After that, instance of TodosVM becomes accessible by components down the component hierarchy.
Notice that withVM hides the implementation details of the viewmodel creation and passing down the components hierarchy.
TodoMVCDisconnectedcomponent is library-agnosticTodoMVCcomponent can be rendered within the library-agnostic componentTodosVMreference only mobx decorators, and it is something which could be easily abstracted out but not in scope of this article
note: in the provided implementation, withVM function relies on the react context API, but you may experiment to find a better-faster-stronger way to implement it.
What’s important is that implementation shall be done in conjunction with the implementation of connectFn (mentioned in the next chapter) in order to ensure that the same viewmodel is reused across all components within the components hierarchy.
7.3. ViewModel facades.
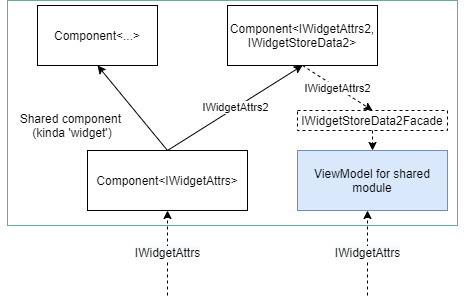
Figure 8: passing the component's attributes 'IWidgetAttrs2' to the viewmodel facade (aka slicing function)
Facade define the class, exposing the subset of the wrapped module instead of its complete interface. Hovewer, creation of the additional classes to wrap the ViewModel is quite verbose.
Instead of classic "facades" let's use functions, which would take a ViewModel (or multiple viewmodels) as an argument(s), and return the data slice of interest. Let's call it slicing function. What if such a function receives the attributes of the component, as its last argument? With single ViewModel in mind, function signature will looks like:
type TViewModelFacade = <TViewModel, TOwnProps, TVMProps>(vm: TViewModel, ownProps?: TOwnProps) => TVMPropsLooks very similar to Redux’s connect function. But instead of mapStateToProps, mapDispatchToActions and mergeProps we have a single function to return both ‘state’ and ‘actions’ from the viewmodel.
Here is the slicing function from provided TodoMVC example:
const sliceTodosVMProps = (vm: TodosVM, ownProps: {id: string, name: string, status: TodoStatus; }) => {
return {
toggleStatus: () => vm.toggleStatus(ownProps.id),
removeTodo: () => vm.removeTodo(ownProps.id),
}
}notice: I am calling component’s attributes as ‘OwnProps’ to align it with terminology, widely spread in the react/redux world.
This similarity drives us to the most convenient way of utilizing such slicing functions within the components tree - using the higher order components.
Assume that the viewmodel is already hosted by the HOC component, created by the withVM function.
Let’s define a signature of a function, which receives slicing function and the component and returns a higher-order component, bound to such a ViewModel.
type connectFn = <TViewModel, TVMProps, TOwnProps = {}>
(
ComponentToConnect: Component<TVMProps & TOwnProps>,
mapVMToProps: TViewModelFacade<TViewModel, TOwnProps, TVMProps>,
) => Component<TOwnProps>
const TodoItem = connectFn(TodoItemDisconnected, sliceTodosVMProps);Rendering of such an item within the items list: <TodoItem id={itemId} name={itemName} status={itemStatus} />
Notice that connectFn hides the implementation details of the reactivity.
- It takes the component
TodoItemDisconnectedand slicing functionsliceTodosVMProps- both unaware of the reactivity library and JSX rendering library. - It returns the component, which will be re-rendered reactively once the data, encapsulated by ViewModel, is modified.
You can check the actual implementation of connectFn in the TodoMVC app.
8. Conclusion:
All features-related code is written using the framework-agnostic syntax. Typescript objects, typescript functions, TSX - that’s all we are bound to.
Guess that after reading this article you might see the benefits of working on SPA architecture ahead of development start. I wish this article would change the mindset from “pick the hyped framework, get the shit done” to “analyse what should be done and define a proper toolset” even for UI applications.
But could the whole presentation layer be framework-agnostic inside the production-grade application?
In order to remove references to mobx, react and mobx-react from presentation layer, we should do slightly more:
- Abstract out mobx decorators
- Abstract out every framework-dependant library, used by the presentation layer. For example provided TodoMVC sample rely on the react-router/react-router-dom libraries.
- Abstract out the synthetic events signatures, specific to particular JSX rendering engine.
First two items are easily manageable and I’ll show you how to handle them in the further articles. But synthetic events abstraction means that we are going to build yet another framework, which would not have the community support behind it.
I am pragmatically choosing to keep referencing react’s synthetic events signatures in mine components. So switching out of the react will require some work, but this work will be localized within the particular components and will not spill through viewmodels or slicing functions.
P.S. Comparison of the suggested structure and it’s implementation to main popular development frameworks:
-
Compared to React/Redux combo: ViewModels replace reducers, action creators and middlewares. ViewModels ARE stateful. No time-travel. Multiple stores. No performance issues caused by excessive connect function usages with some logic inside. Redux-dirven apps tend to become slower over time while more and more connected components are being added to application, so there is no evident bottleneck to fix. Slicing function implementation given in the example is not affected by this issue, kudos to mobx dependencies tracking. Although, it can be achieved with another reactive UI library as well.
-
Compared to vue: Strongly typed views cudos to TSX. Viewmodels are native class instances without framework-specific syntax blended in. Vue.js forces the definition of state to be done within the objects of specific structure having ‘data’,’methods’, etc. properties. Absence of vue-specific directives and model binding syntax.
-
Compared to angular: Strongly typed views kudos to TSX. Absence of angular-specific directives and model binding syntax within the html. Prevent views from direct manipulations on the state (aka on the component public fields, aka two-way data binding). Hint: for some scenarios (such as forms) two way data binding might be preferred.
-
Compared to pure react with state managed through hooks (such as useState/useContext): better separation of concerns. VMs could be meant like the container components, however they do not render anything and subsequently it is much harder to mess up the state management logic and UI code.
Avoid the necessity to care about hooks sequence, about keeping the useEffects dependencies tracked in the ‘deps’ array, about managing component’s mount status with regards to async actions, about making sure closures from ‘previous’ renders are not suddenly used during effect execution.
As any other tech, hooks (and in particular - useEffect) requires developer to follow some recommendations (not declared in the interface, but accepted as a ‘approach’, ‘mental model’ or ‘best practices’). There is a nice guide to useEffect from one of the react team members. Read it and then answer two questions:
- What do you achieve with hooks?
- How many rules, not controlled by the compiler and hardly tracked by linter/visual code review, should be followed by the developer while working with hooks in order to make them predictable? Once the second list exceeds the first one by a huge margin - it is a good sign to me that an approach should be considered with a huge caution. hint: tiny bit of frustration about hooks
-
Compared to react-mobx integration. Code structuring is not defined within the shipped in react-mobx docs. It is up to the development team. You may consider an approach, described in this article as an approach to structure the application written with react for rendering and mobx for state management.
-
Compared to mobx-state-tree: Viewmodels are native class instances without framework-specific syntax blended in. Mobx-state-tree types definitions heavily rely on the framework specific syntax. Mobx-state-tree may force the duplication of code while declaring the types because properties of concrete type should be described both in the typescript interface and in the model definition.